シングルテーブル設計についてまとめてみた【DynamoDB】
Kei
printf!

本ページでは、AWS DynamoDBのLSI (Local Secondary Index)って結局何なのか?を図を使ってまとめてみました。
LSI、分かったような、分かってないような…という方に、「あ~なるほどね」と思っていただけることを目指して整理してみました!

AWS 認定ソリューションアーキテクト アソシエイト
(AWS Certified Solutions Architect – Associate, SAA)
AWS 認定デベロッパー アソシエイト
(AWS Certified Developer – Associate, DVA)
AWS DynamoDBにおけるLSI(ローカル・セカンダリ・インデックス)とは、
パーティションキー(PK)とソートキー(SK)以外の属性を
ひとつ選択し、それを新たなソートキーとして作成するインデックス
(≒クエリ専用テーブル)
です。
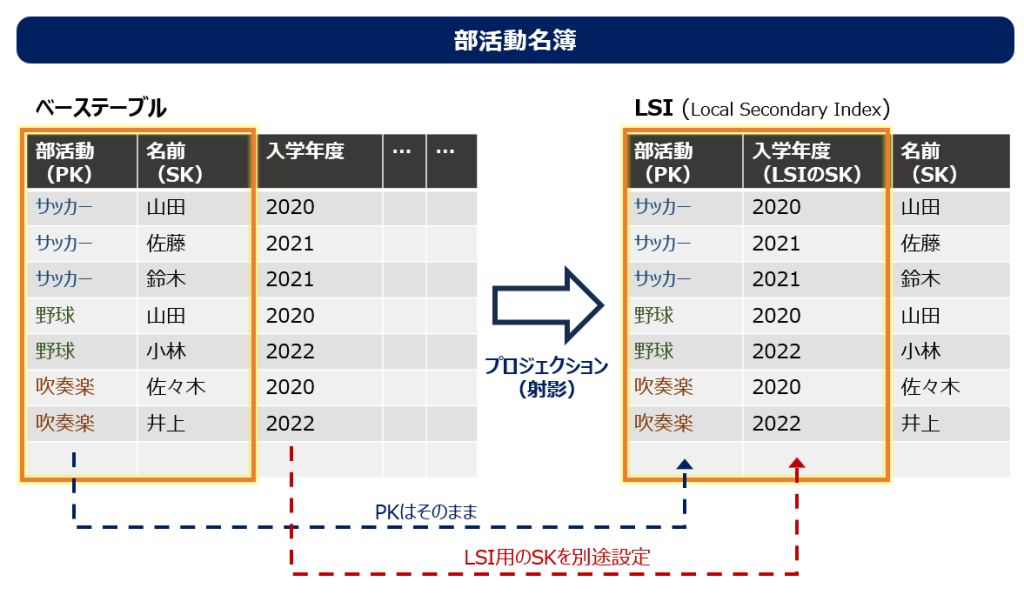
上の図では、部活動名簿を例として挙げています。本体のテーブル(ベーステーブル)では、PKに部活動、SKに名前が設定されているため、入学年度でクエリすることはできません。もし、「サッカー部の2021年度入学の生徒」をクエリしたい場合、サッカー部全員分を一度読み込む必要があります。
Query APIでは FilterExpression で絞り込み条件を設定できますが、これは読み込んだ結果に対して追加の絞り込みをしているだけなので、「かかる時間やお金」は絞り込み無しの場合と同じです。
そこでLSIを作成し、そのSKとして入学年度を指定します。これによって、SKが入学年度であるテーブルがもう一つ作成されたような状態になります。これがインデックスです。
このLSIを使うことで、「サッカー部の2021年度入学の生徒」を、無駄なデータを読み込むことなく効率的にクエリすることができます。
同じ読み込み操作でも、GetItemやBatchGetItemは使用できません。
また、そもそもインデックスは「データを効率的にクエリ(読み込み)するするための仕組み」ですので、LSIを使った書き込み操作(PutItem, UpdateItem, DeleteItem)はできません。
LSI用に新しく設定できるのはSKだけで、PKはベーステーブルのものが引き継がれます。
つまり、LSIを設定したとしても、PKを跨いだクエリはできません。
そして、これがGSI(Global Secondary Index)との一番の違いです。PKを跨いで、テーブル全体でクエリしたい場合はGSIを使用します。
ベーステーブルのPKが引き継がれるというのは、物理的には「ベーステーブルと同じパーティション内にLSIのデータが格納される」という意味です。LSIのクエリも、結局もとのパーティションの中で完結するので、Local (ローカル)という名前が付いています。
また、LSIはテーブル新規作成時にしか設定できず、テーブル作成後に追加設定は不可です。これも、上記のデータ格納方法の仕組みなどから発生している制約です。
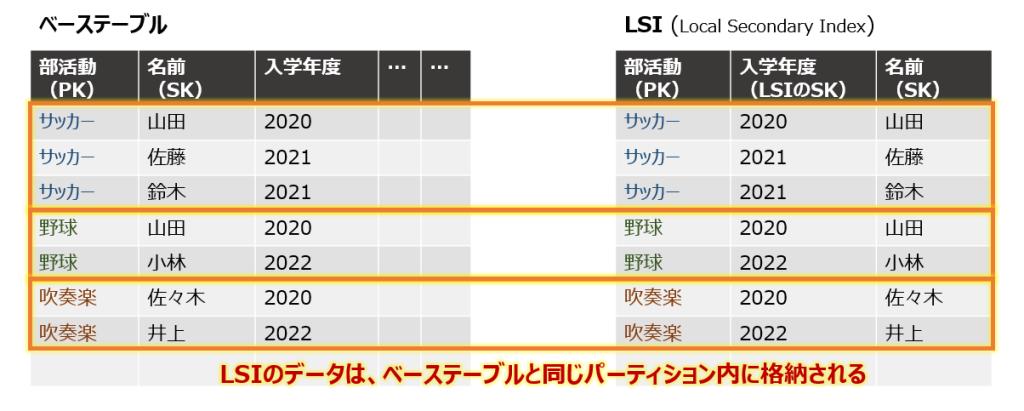
同じパーティション内に、LSI用にデータが複製されることになるので、容量にも制限があります。「単一PKの全LSIデータの合計が10GBまで」という制限です。
仕組みはシンプルで、「LSI用にコピーされたデータの分だけ、追加でお金がかかる」というだけの話です。
LSIのプロジェクション設定(≒LSIにどれだけデータをコピーするか)には、下記の3種類があります。❶Allは丸ごとコピーされるのでストレージ料金も2倍になってしまいます。❷Includeや❸KeysOnlyによって、データ量を必要最小限に絞っておくのが重要です。
上で紹介している部活動名簿の例では、KeysOnlyになっています!
LSIにおける読み込み/書き込みの動作は下記の通りです。オンデマンド/プロビジョニング問わず、ベーステーブルと同じ仕組みの中で処理されます。
なお、書き込みにおいてユーザーはLSIを意識する必要はなく、ベーステーブルに書き込み操作を行うと勝手にLSIにも同じ内容が書き込まれます。
LSIを使用したクエリでは、クエリしたデータ量に応じてキャパシティユニットを消費します。LSIから読み込んだからといって追加消費は発生しません。
ベーステーブルとLSIの両方の書き込みに対してキャパシティユニットを消費します。つまり、基本は2倍消費します。
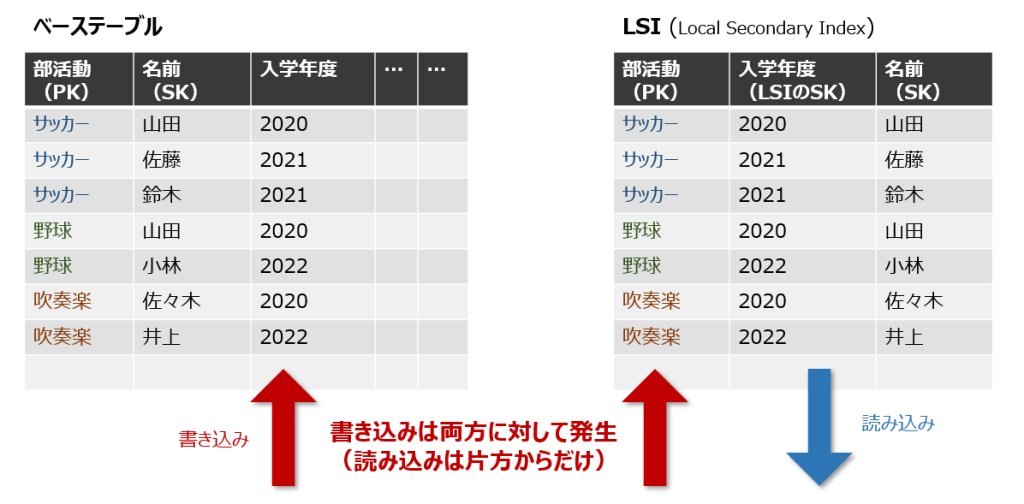
要注意なのは書き込みですね。こちらも、プロジェクションの設定をAllにしておくと全項目が二重に書き込まれてしまいますが、KeysOnlyなどにしておけば、書き込み量を抑えることができます。
上で解説した通り、LSIを設定した途端に、ストレージや読み込みで余計なコストが発生してしまいます。このため、必要でないなら設定しないのが基本です。
一方、下記のような場合はLSIを設定することで、クエリが効率化されてアプリのパフォーマンス向上やコスト削減が期待できます。ただし、もし複数個のインデックスが必要になる場合は、そもそもテーブルを分割するなどの見直しが必要な可能性がありますので、気を付けてくください。
ここまで、AWS DynamoDBのLSIについてまとめました。
一言で言ってしまえば、「既存のPKと、新たなSKによって、新しいテーブルが作成される」という動きをしています。
LSIの中身の動きを理解しておくことで、AWS側で設定されている料金や制約といった仕様もスッと頭に入ってくるのではないでしょうか?この記事が、少しでもLSIの理解の助けになれば幸いです。






